
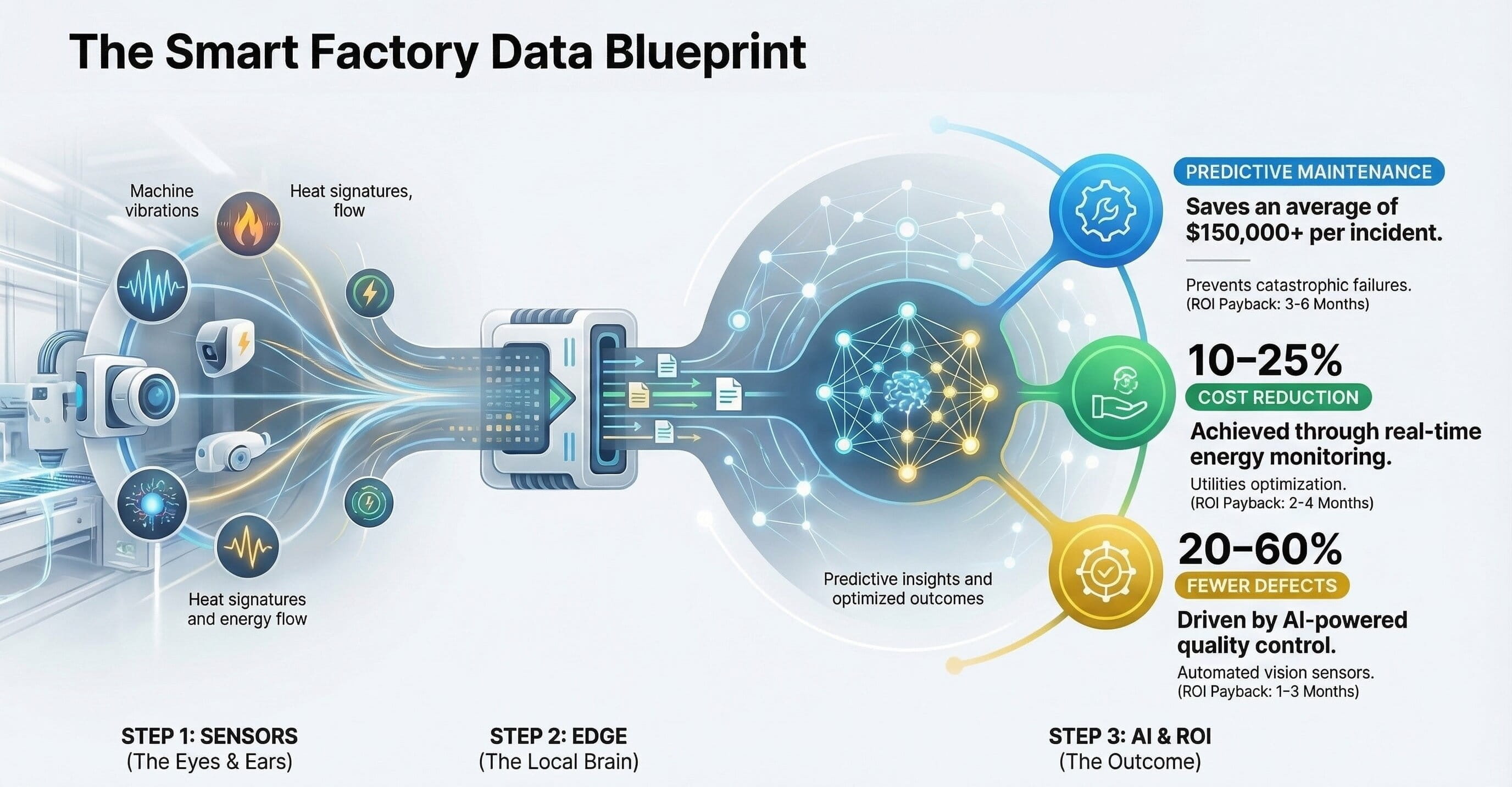
Executive Summary
Manufacturing leaders have no shortage of data. They have PLC streams, SCADA alarms, historian archives, MES transactions, quality records, CMMS work orders, laboratory systems, ERP master data, energy data, and increasingly, computer vision and AI signals. The problem is not data generation. The problem is architectural coherence. When the industrial data estate is fragmented, each new use case becomes a custom integration exercise, every KPI turns into a debate, and analytics programs struggle to move from pilot value to enterprise impact.
A smart factory data blueprint solves that by defining how data is captured, normalized, contextualized, governed, stored, analyzed, and operationalized. It turns plant signals into a reusable business asset rather than a collection of isolated technical feeds.
Why Smart Factory Programs Stall Without a Data Blueprint
The visible symptom: too many dashboards, too little action
Most manufacturers already have reporting tools. Yet teams still rely on manual reconciliation, tribal knowledge, and spreadsheet stitching because raw machine data alone does not explain what happened, why it happened, or what should happen next.
The hidden cause: architecture built use case by use case
When connectivity, storage, semantics, and ownership are designed separately for each initiative, the result is duplicated pipelines, inconsistent definitions, fragile integrations, and growing security exposure.
| Without a blueprint | With a blueprint |
|---|---|
| Point integrations around immediate needs | Reusable architecture aligned to long-term plant and enterprise value |
| KPI disputes across functions and sites | Shared semantic definitions and governed data contracts |
| Analytics teams spend most time cleaning data | Analytics teams focus on optimization and decision support |
| Pilots are hard to scale | New use cases inherit a stable foundation |
| OT/IT tension increases with each integration | Clear interface model, security boundaries, and ownership |
The Smart Factory Data Blueprint: Seven Essential Architecture Layers
The strongest industrial data architectures are layered by responsibility. Each layer solves a different problem, and confusion begins when companies merge all responsibilities into one platform label.
1. Source Systems Layer
This is where operational reality originates: PLCs, DCS, SCADA, historians, MES, LIMS, CMMS, ERP, energy systems, warehouse systems, and increasingly smart sensors, cameras, and embedded edge devices.
- Define which systems are systems of record.
- Separate raw telemetry from transactional plant events.
- Catalog critical asset, line, batch, order, material, and quality identifiers.
2. Connectivity & Ingestion Layer
This layer handles secure extraction and movement of data from OT and IT sources into the wider data backbone. It should support both real-time and scheduled patterns without bypassing control boundaries.
- Use protocol-aware industrial connectors where needed.
- Prefer standardized and observable ingestion patterns.
- Design for buffering, retry, timestamp quality, and edge resilience.
3. Context & Semantic Layer
This is the layer many programs miss. Machine tags become business-ready only when linked to equipment hierarchies, product context, batches, shifts, operators, orders, material lots, maintenance states, and process phases.
- Standardize naming conventions and asset models.
- Link events, telemetry, and production context.
- Make relationships explicit so metrics remain stable over time.
4. Storage Layer
Not all industrial data belongs in one storage pattern. High-frequency telemetry, structured events, documents, contextual models, and curated analytic datasets need different retention, performance, and governance treatments.
- Balance hot, warm, and historical workloads.
- Retain lineage from raw to curated data.
- Avoid uncontrolled replication across tools.
5. Analytics & Intelligence Layer
This is where manufacturing intelligence is generated: OEE, downtime root cause analysis, quality drift detection, energy optimization, predictive maintenance, schedule adherence, throughput diagnostics, and AI-assisted recommendations.
- Build from governed features, not ad hoc extracts.
- Keep explainability and traceability visible.
- Tie insights to accountable business action owners.
6. Operational Action Layer
A data architecture creates value only when it changes action. Alerts should trigger workflows, recommendations should reach teams in context, and exception patterns should feed planning, quality, or maintenance processes.
- Route outputs into operator, engineer, planner, and supervisor workflows.
- Use escalation logic and thresholds linked to plant reality.
- Measure decision latency, not just dashboard usage.
7. Governance, Security & Lifecycle Layer
This cross-cutting layer ensures the blueprint remains safe, trusted, and maintainable. It covers ownership, access control, lineage, quality rules, model versioning, auditability, change management, and rollout standards across sites.
- Assign accountable owners for asset models, KPI definitions, and source interfaces.
- Apply role-based access and plant-aware segmentation.
- Control schema changes and manage lifecycle transitions deliberately.
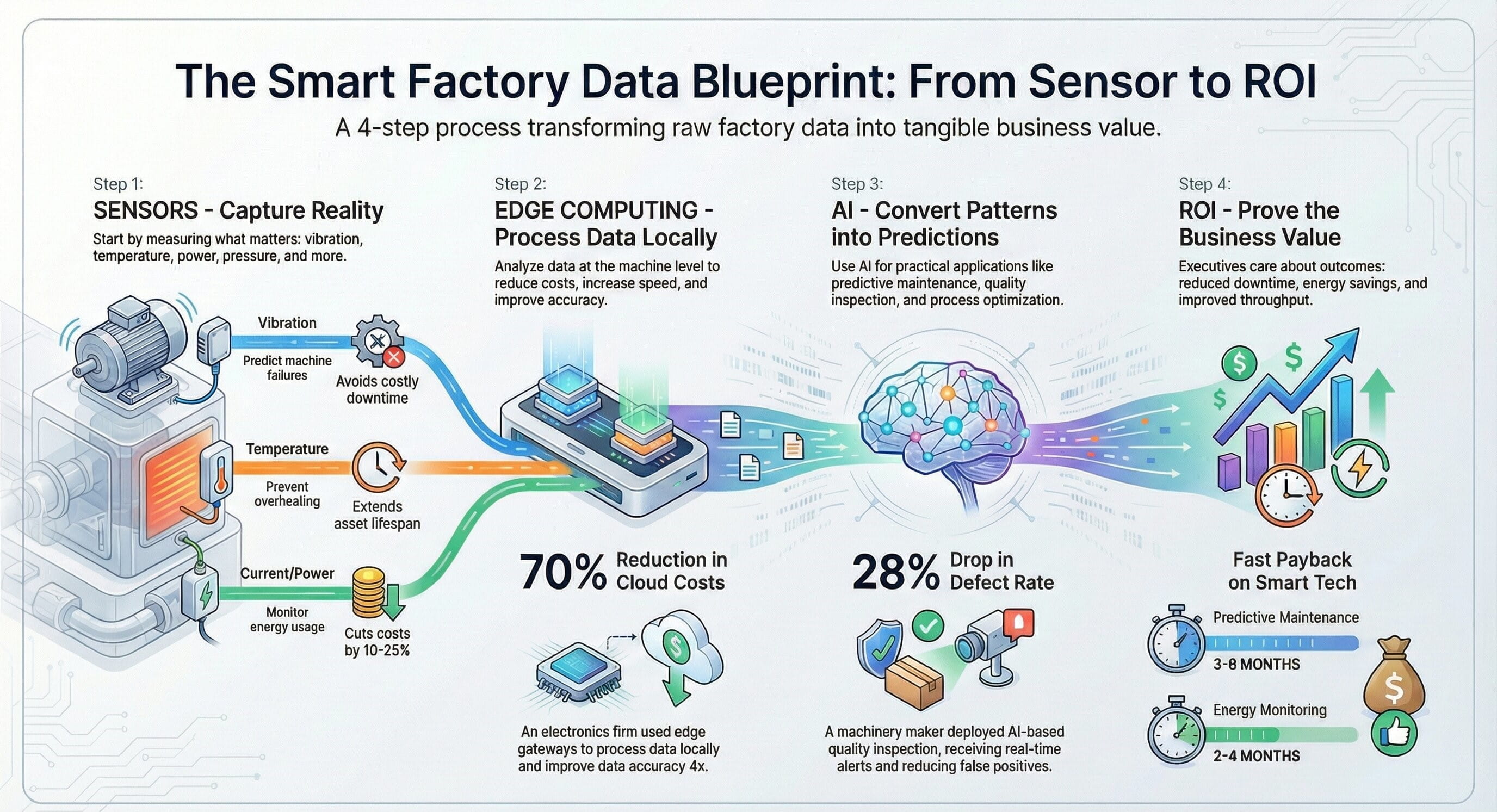
The Governance Model That Makes the Blueprint Work
Data ownership
Every critical domain needs named ownership. Equipment structures, production orders, quality events, downtime codes, and maintenance references cannot remain “everyone’s problem.”
Semantic discipline
If one plant defines runtime, micro-stop, yield, or scrap differently from another, enterprise comparison becomes fiction. Governance must standardize meanings before scale.
Change control
New tags, renamed assets, changed recipes, and modified KPI logic need controlled release discipline. Otherwise, analytics drift silently and trust collapses.
ROI Model: How the Blueprint Pays for Itself
Executives rarely fund “better data” in the abstract. They fund measurable operational and financial outcomes. The smart factory data blueprint should therefore be justified as a reusable value engine, not a technology refresh project.
| Value lever | How architecture contributes | Typical executive relevance |
|---|---|---|
| Throughput improvement | Aligns machine state, process performance, and scheduling context to identify bottlenecks faster | Revenue, on-time delivery, asset utilization |
| Quality reduction in waste | Joins process conditions, quality outcomes, and material lineage for earlier intervention | Margin, customer performance, compliance |
| Maintenance efficiency | Connects condition signals, work order history, and criticality context to improve prioritization | Availability, labor productivity, spare parts use |
| Energy optimization | Relates consumption to output, asset state, and operating mode instead of viewing utility data in isolation | Cost control, sustainability, carbon reporting |
| Faster deployment of new use cases | Provides reusable ingestion, semantics, and governance rather than starting from scratch | Transformation velocity, capex efficiency |
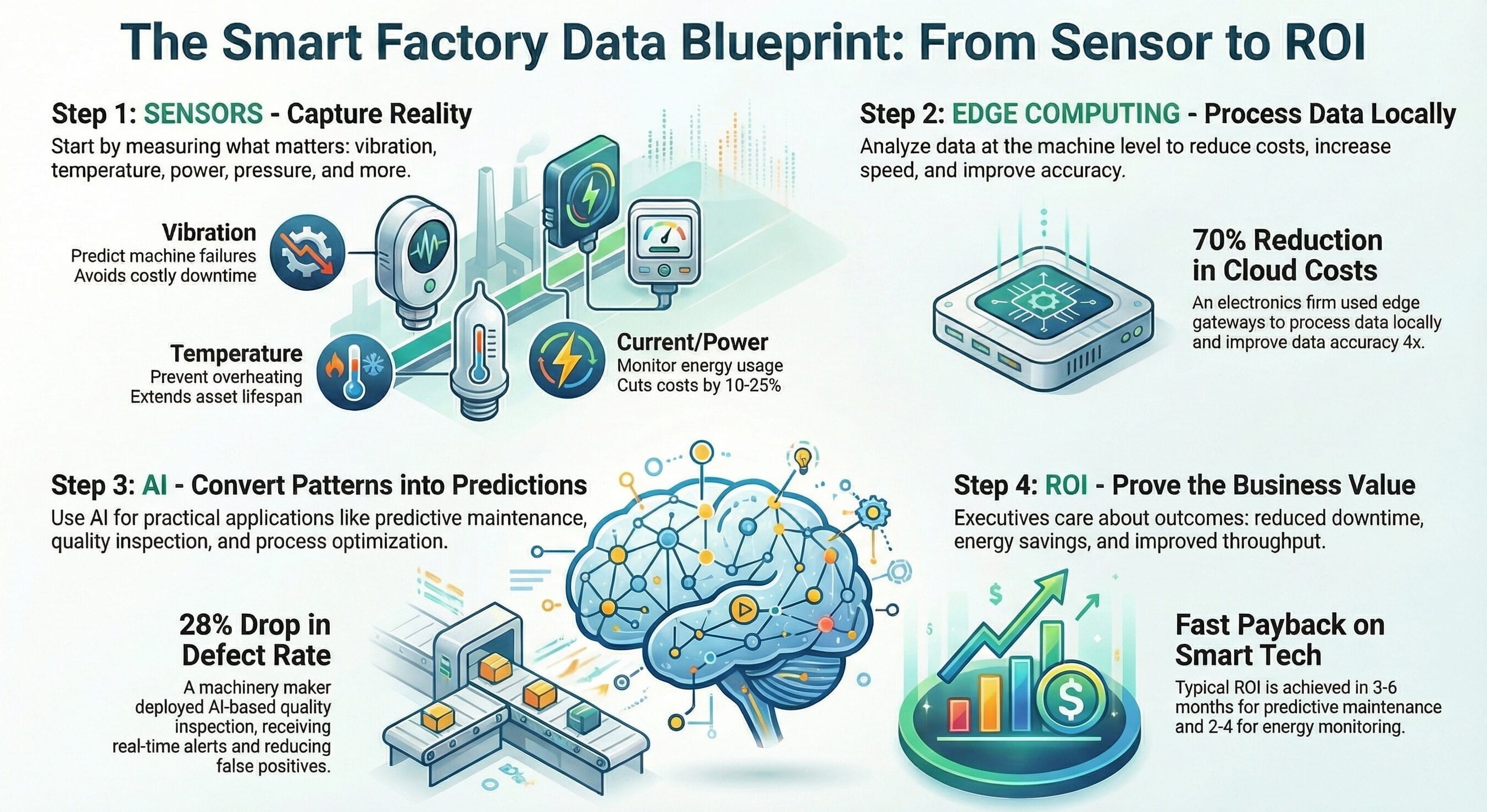
Implementation Roadmap: How to Move from Concept to Scalable Execution
Start with one value stream, not the whole enterprise
Choose a line, plant area, or product family where downtime, quality, throughput, or energy performance already matter financially. The goal is architectural proof with operational value, not abstract technology validation.
Define the data contract before building pipelines
Clarify identifiers, timestamps, state models, event logic, quality rules, and KPI definitions before large-scale integration work begins. This prevents expensive redesign later.
Build context as a first-class capability
Do not stop at connectivity. Join telemetry with orders, batches, material, shift, asset hierarchy, quality disposition, and maintenance history so the data is usable outside the engineering team.
Operationalize insight into workflow
Push alerts, exceptions, recommendations, and KPIs into the environments where teams already work. Architecture creates value only when it changes decisions and response behavior.
Scale with standards, not duplication
Once the first deployment proves value, replicate through reference models, reusable ingestion patterns, governance templates, and site onboarding playbooks rather than rebuilding from scratch.
What Leadership Teams Should Ask Before Approving the Program
Strategic questions
- Which operational outcomes justify the investment first?
- Which plants or value streams should become the reference model?
- How will we define success beyond dashboard adoption?
- What data domains are truly enterprise critical?
Architectural questions
- Where will context be created and maintained?
- How are OT and IT responsibilities separated and coordinated?
- What governance body owns semantic consistency across sites?
- How will new AI use cases consume trusted industrial data without bespoke rework?
Watch the Blueprint
Video brief
For stakeholders who prefer a visual walkthrough, this embedded video slot can be used inside the same blog flow without leaving the page.
Listen to the audio version
For readers who want the narrative in a portable format, the audio version can sit directly beside the video and written summary.
Final Takeaway
The smart factory is not built by collecting more machine data. It is built by designing a reliable architecture that turns industrial signals into operational context, governed insight, and repeatable action. Manufacturers that treat the data backbone as strategic infrastructure will move faster on analytics, AI, quality, maintenance, energy, and multi-site standardization. Manufacturers that continue building one-off integrations will keep paying for the same foundational problem again and again.
Enhanced Full Blog Text — Board-Ready Report Format
The Smart Factory Data Blueprint: How to Build a Scalable Industrial Data Architecture for Real-Time Operations, AI, and Continuous Improvement
Executive perspective: Smart factory transformation succeeds when industrial data stops behaving like a set of disconnected technical exhaust streams and starts behaving like a managed operating asset. The central challenge is not whether plants can produce data. They already do. The challenge is whether manufacturers can transform that data into a dependable, contextualized, governed foundation that supports real-time operations, cross-functional visibility, and scalable AI adoption. This blueprint explains how to do that in a disciplined way.
The real problem is fragmentation, not instrumentation
Many manufacturers begin digital transformation with a false assumption: that the main barrier is missing data. In reality, the larger barrier is that available data is scattered across incompatible systems, collected under different ownership models, and interpreted through inconsistent operational definitions. PLCs provide control-level signals. SCADA and historians capture process behavior. MES tracks execution. Quality systems record inspection outcomes. Maintenance systems hold work order history. ERP contains master data, demand signals, and cost context. Each source is useful in isolation, but none provides a complete picture of performance on its own.
That is why many factories become data rich yet insight poor. Teams can see alarms, trends, and reports, but they still struggle to answer the questions that matter most: What actually happened? Under what operating context? Which business variables were affected? What action should follow? Which cross-functional owner is accountable?
Why a blueprint matters
A smart factory data blueprint provides a structured answer to those questions. It defines how information flows from operational and enterprise systems into a shared architecture. It determines where data is standardized, where context is added, where trust is established, where access is governed, and where insights are translated into action. Without this blueprint, every new use case becomes a reinvention exercise. One team builds a pipeline for downtime reporting. Another builds a separate extract for quality dashboards. A third builds a custom model for predictive maintenance. Over time, the architecture becomes more expensive, less governable, and harder to scale.
In strategic terms, the blueprint converts digital transformation from a project portfolio into an industrial capability. It is what allows a company to create value repeatedly rather than episodically.
The architecture begins with source clarity
The first step is to define the source landscape clearly. Source systems are not just technical endpoints. They are operational authorities. A PLC may be the authority for machine state transitions. MES may be the authority for production order execution. ERP may be the authority for product, customer, and material master data. Quality systems may be the authority for defect classes and release decisions. Maintenance systems may be the authority for repair history and asset criticality. The blueprint must document which systems are authoritative for which categories of information.
This matters because many industrial programs quietly fail when they allow multiple unofficial copies of the same concept to proliferate. Once teams start calculating downtime, yield, runtime, micro-stop, or defect rates differently across plants, executive confidence in the data erodes. The blueprint prevents that by anchoring every major metric to a governed source and a shared definition.
Connectivity alone is not enough
Once source systems are understood, data must be moved securely and reliably. This is the job of the connectivity and ingestion layer. In many factories, this stage receives disproportionate attention because it is tangible. Teams can point to connected machines, active brokers, API flows, and streaming data pipelines as evidence of progress. Yet connectivity is only one part of the solution. It gets signals into the architecture, but it does not make them decision-ready.
A machine current reading is not meaningful by itself. An alarm feed is not sufficient by itself. A temperature trend is not useful by itself. These signals gain value only when paired with business and operational context. In other words, a connectivity-first program may produce more visible data, but it does not necessarily produce more actionable intelligence.
Context is the most important design choice
The contextualization layer is the heart of the smart factory data blueprint. This is where telemetry becomes explainable. Machine readings are mapped to asset hierarchies. Process signals are linked to production orders, recipes, lots, shifts, and operating modes. Quality outcomes are linked to the exact process conditions under which they emerged. Maintenance events are tied to the asset state and production consequences around them.
Without this layer, organizations may still create dashboards, but those dashboards remain descriptive rather than operational. They show what moved, but not why. They report performance, but not the business circumstances that generated it. This is why contextualization should be treated not as data enrichment at the end of the pipeline, but as a core architectural capability from the start.
For manufacturers planning AI adoption, this point is even more critical. AI models depend on consistent, labeled, context-rich data. If semantic structure is weak, model development turns into a repetitive clean-up effort. The cost of every use case increases, and trust in the outputs decreases.
Storage should reflect workload reality
Another common mistake is to assume that all industrial data belongs in a single storage pattern. It does not. High-frequency process telemetry has different performance and retention requirements from event streams, structured transactions, document records, semantic models, and curated feature sets. The storage layer should therefore be designed around access patterns, data criticality, latency needs, and governance rules rather than vendor convenience.
A mature blueprint preserves lineage from raw source capture to curated decision-grade datasets. It does not allow uncontrolled copying between tools without accountability. That lineage is essential for auditability, reproducibility, and cross-functional trust—particularly in regulated industries or environments where operational decisions have quality, safety, or customer consequences.
Analytics should begin with decisions, not dashboards
The analytics and intelligence layer is where most transformation programs expect visible value. That expectation is fair, but only when the layer is designed to support decisions rather than presentation alone. A smart factory should be able to detect abnormal behavior, explain likely causes, recommend action paths, and feed those actions into real workflows. That can include OEE diagnostics, downtime root cause patterns, yield loss analysis, maintenance prioritization, bottleneck monitoring, energy optimization, and AI-supported scenario evaluation.
However, analytics maturity depends heavily on upstream design quality. When data arrives late, inconsistently labeled, or without stable definitions, analytics becomes an exercise in narrative reconstruction rather than performance acceleration. The blueprint therefore ensures that analytic consumers inherit governed data products rather than unstable extracts.
Operational action is where value is realized
Many digital programs unintentionally stop at insight. They generate reports, flags, or predictive outputs, but fail to connect them to plant workflows. The blueprint must explicitly define how insight becomes action. Which alerts should go to operators? Which should route to supervisors? Which should create maintenance work orders? Which should escalate to process engineering? Which conditions justify intervention? Which outcomes should be measured afterward?
This action model is what shortens decision latency. It transforms data from an observation layer into a performance system. The best smart factories do not merely display information faster. They make it easier for teams to act correctly, consistently, and with shared understanding.
Governance is the scaling mechanism
Governance is often misunderstood as an overhead function. In reality, it is the mechanism by which a smart factory blueprint remains coherent over time. Industrial environments change continuously. New machines are added. Asset names change. Product mixes evolve. Plants expand. Sites interpret rules differently. Vendors introduce updates. Without governance, architecture entropy grows rapidly.
Governance must cover ownership, access, semantics, lineage, change management, and lifecycle controls. There should be named accountability for asset hierarchies, KPI definitions, master data harmonization, interface changes, and rollout standards. This is especially important in multi-site enterprises where local pragmatism can quietly undermine enterprise comparability.
Good governance accelerates scale because it reduces the cost of re-interpretation. Once definitions, patterns, and standards are reusable, onboarding additional plants becomes materially easier.
How the blueprint creates financial value
Leadership teams need a clear investment case. The strongest ROI cases come from measurable operational levers. A governed industrial data backbone can reduce unplanned downtime by improving condition awareness and maintenance prioritization. It can improve yield by linking process states and material conditions to quality outcomes earlier. It can increase throughput by exposing bottlenecks in real time and supporting more coordinated action between planning, operations, and engineering. It can reduce energy waste by making consumption visible in relation to output and operating mode rather than in disconnected utility reports.
There is also a strategic return that is often underestimated: the reduction in future use-case cost. Once ingestion, context, semantics, governance, and storage patterns are established, each new digital initiative requires less rework. This lowers the marginal cost of innovation and increases transformation speed.
A practical roadmap for execution
The recommended rollout path is disciplined and phased. Begin with one value stream or plant area where economic impact is visible and leadership attention exists. Do not attempt to digitize the entire enterprise at once. Define the data contract before heavy engineering begins. This includes identifiers, timestamps, event logic, state models, and KPI rules. Build contextualization as a first-class capability rather than treating it as a later enhancement. Then ensure that insights are operationalized into workflows, not left as standalone reports.
Once the first deployment proves value, scale through standards, reference models, and playbooks. Replication should not mean duplication. The objective is not to rebuild the architecture plant by plant. The objective is to create a reference blueprint that can be adapted consistently across sites with controlled variation.
What executives should remember
The smart factory is not a sensor strategy. It is not a dashboard program. It is not a data lake by itself. It is an architectural discipline that enables industrial decisions at scale. The manufacturers that lead in this space will be the ones that treat data context, governance, and operational integration as strategic capabilities. They will see faster value from analytics, more reliable AI adoption, stronger cross-functional alignment, and greater resilience as plants and products change.
The manufacturers that do not adopt this mindset will continue to fund isolated use cases that solve symptoms while leaving the foundational problem intact. Over time, those organizations accumulate complexity without compounding value. The smart factory data blueprint is the mechanism that reverses that pattern.
Final conclusion: a scalable smart factory begins with a scalable industrial data architecture. When that foundation is designed intentionally, every subsequent optimization effort becomes more credible, more governable, and more economically valuable.
Daniel updated on 19 Nov 2025, 08:15AM
This is one of the better explanations I’ve seen of why manufacturers need to separate data transport, context, and consumption. Too many projects still assume a dashboard equals a data strategy.Kavya updated on 19 Nov 2025, 10:02AM
Agreed. The context layer stood out to me. We have plenty of machine data already, but very little production context around order, operator, material lot, or shift. That is exactly why analytics adoption has been weak.Jonas updated on 19 Nov 2025, 01:28PM
The phased rollout section is practical. Starting with one value stream and proving downtime, scrap, and OEE improvement is far more realistic than trying to “digitize the whole factory” in one budget cycle.Priya updated on 20 Nov 2025, 09:11AM
The point about historian data not being enough for enterprise-scale optimization is important. We learned that the hard way once quality, maintenance, and ERP data needed to be joined in near real time.Felix updated on 20 Nov 2025, 11:47AM
Yes, and the governance angle matters just as much. Our pilot worked technically, but failed to scale because no one owned tag standards, asset hierarchies, or KPI definitions across sites.Hannah updated on 20 Nov 2025, 03:36PM
The architecture layering is clear. I especially liked the distinction between ingestion, contextualization, storage, analytics, and operational action. Many vendors compress all of that into one box and create confusion.Arjun updated on 21 Nov 2025, 08:54AM
Would be great to see more manufacturers treat event models and semantic modeling as first-class design decisions. Without them, AI use cases become expensive clean-up exercises.Lena updated on 21 Nov 2025, 12:20PM
Exactly. The article makes the right point: AI readiness is not a tool purchase, it is a data discipline problem first.Tobias updated on 21 Nov 2025, 04:05PM
The security section is balanced. Plant leaders often worry that more connectivity automatically means more risk, but a structured architecture with segmentation, identity, and monitored interfaces is actually safer than ad hoc integrations.Meera updated on 22 Nov 2025, 09:32AM
The ROI framing is useful for leadership discussions. Boards rarely approve “data modernization” on abstraction alone, but they will support a roadmap tied to throughput, energy, maintenance, and quality economics.Oliver updated on 22 Nov 2025, 02:18PM
I also appreciated that the article did not oversell full autonomy. Most factories still need a strong human-in-the-loop model, especially in quality, maintenance planning, and exception handling.Nikhil updated on 23 Nov 2025, 10:06AM
The implementation roadmap is close to what we are doing now: standardize the data contract, build one governed pipeline, contextualize the assets, and only then expand to multi-site analytics.Greta updated on 23 Nov 2025, 01:41PM
That sequence matters. We skipped standardization at first and spent months reconciling naming differences between otherwise identical production lines.Samuel updated on 24 Nov 2025, 08:27AM
Strong article. The core message is right: the smart factory is not built on isolated use cases; it is built on a reusable industrial data foundation that makes new use cases cheaper and faster over time.